1.1 Database and Instance
- Oracle Database Server(Oracle Database) = Database + Database Instance
- Database
- 디스크에 위치한 파일 집합
- Database Instance
- SGA(system global area)+Background Process
- 데이터베이스 파일을 관리하기 위한 메모리 구조의 집합으로 공유 메모리와 프로세스로 구성
- Client Process가 인스턴스에 접속하여 Session이 설정되면 Server Process가 생성됩니다.
- Server Process는 공유하지 않는 개별 세션 메모리인 PGA(Program global area)를 보유하고 있습니다.
- Database
1.2 Database Storage Structures
1.2.1 물리적인 저장 구조
- 데이터베이스 파일 저장 메커니즘
- Automatic Storage Management (ASM)
- 오라클 데이터베이스용으로 구축된 파일 시스템 및 볼륨 관리(디스크 관리)를 위한 SW
- 고가의 RAID 장비(타사 OS 볼륨관리 및 파일 시스템 관리)를 ASM 으로 대체
- 균일한 성능 제공을 위해 디스크에 균일하게 데이터 분산
- 디스크 추가 등 구성이 변경되면 데이터를 자동으로 재 배치
- EXA에서 사용
- 데이터베이스는 데이터 파일, 컨트롤 파일, 온라인 리두 로그 파일 및 기타 유형의 파일을 ASM 파일로 저장 가능
- Automatic Storage Management (ASM)
데이터베이스 파일
- 데이터 파일(Data files)
- 데이터가 저장되는 파일
- 데이터베이스의 데이터는 각 테이블스페이스의 데이터 파일의 집합에 저장
- 테이블스페이스의 데이터 Dictionary 저장 (테이블 및 인덱스와 같은 데이터베이스 구조 포함)
- v$datafile, v$tempfile
- Control files
- 데이터베이스의 물리적 구조를 저장한 파일
- 데이터베이스 이름, 데이터베이스 ID, 데이터 파일, 리두로그 및 아카이브 파일 정보, 현재 로그 번호, 체크포인트 정보 포함
- binary 파일로 CREATE CONTROLFILE 명령어로 생성 가능
- ALTER DATABASE BACKUP CONTROLFILE TO TRACE AS ‘D:\trace_cf.txt’; 명령어로 text파일로 변환하여 확인 가능
- v$controlfile
Redo log files
- DB에서 발생한 모든 변경 작업을 기록한 파일
- 데이터 복구에 사용
- v$log, v$logfile
- 장애 대비를 위한 리두로그 파일 다중 관리
- 리두로그 그룹: 온라인 리두 로그 파일과 복사본으로 구성
- 멤버 : 리두 로그 파일 및 복사본 파일
- redo log switch 발생할 때 checkpoint 발생과 함께 dbw에 적음.
- 보통 5개 파일 정도(요즘은 보통 1G)
- 파일이 3개redo1,redo2,redo3 일 때 redo3도 다 차서 다시 redo1로 갈 때 redo1의 checkpoint 프로세스가 안 끝나고 있으면 db가 멈추기 때문에 순환이 되기 전에 checkpoint가 다 끝나도록 튜닝 필요.
- rac의 경우
- 인스턴스별로 log파일 존재
- 데이터파일은 공유하지만 로그는 인스턴스 별로 존재
1.2.2 논리적인 저장 구조
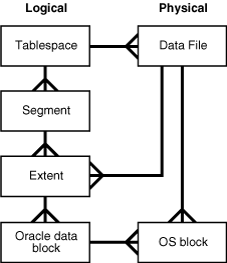
- 데이터 블록 (Data blocks)
- 데이터베이스 I/O의 최소 단위
- 데이터 블록은 OS 블록으로 구성
- 데이터베이스가 생성될 때 데이터베이스의 데이터 블록 크기를 설정(DB_BLOCK_SIZE)
- 익스텐드(Extents)
- 논리적으로 연속된 데이터 블록 집합
- 익스텐드는 항상 하나의 데이터 파일에 포함
세그먼트(Segments)
- 테이블 스페이스 내의 논리적 저장 구조
- 테이블/인덱스와 같은 Schema Object에 할당된 익스텐트 집합
- 한 개 이상의 데이터 파일을 가질 수 있음
- 한 개의 테이블스페이스에 속함
- LOB 데이터는 별도 세그먼트에에 저장
테이블스페이스(Tablespaces)
- 하나 이상의 세그먼트로 구성
- 데이터베이스는 테이블스페이스라는 논리적 저장 단위 구성
- 테이블스페이스는 하나 이상의 데이터파일 또는 임시파일에 데이터를 저장
- 각 데이터베이스 사용자는 기본 영구 테이블스페이스(Permanent Tablespace)데이터베이스 할당
- SYSTEM
- SYS 사용자가 소유
- data dictionary
- 데이터베이스에 대한 관리 정보가 포함된 테이블 및 뷰
- 트리거, 프로시저, 패키지 등의 컴파일된 저장 객체
- SYSAUX
- SYSTEM 테이블스페이스의 보조 테이블스페이스(auxiliary tablespace)
- UNDO
- 시스템에서 관리하는 실행취소(undo) 데이터를 위해 지정된 테이블스페이스
- 인스턴스당 한 개만 보유
- SYSTEM
1.3 Oracle Instance Architecture
1.3.1 데이터베이스 인스턴스
- 데이터베이스 인스턴스 식별
- Oracle Base Directory : 오라클 DB 설치 소유자의 홈 디렉토리로 SW와 구성 파일 저장 위치
- Oracle Home Directory : 오라클 DB SW 홈 디렉토리로 Oracle Base 하위 디렉토리
- Oracle System Identifier(SID) : Host의 오라클 데이터베이스 인스턴스에 대한 고유이름
- 인스턴스 및 데이터베이스 시작 순서
- Initializaion Parameter Files
- 오라클 메모리 구조와 데이터베이스 인스턴스 설정 파일
- 데이터베이스 시작 맨 처음에 읽는 파일
- spfile(binary), pfile(text)
- 노드가 많으면 (RAC 처럼) SP파일 사용
- 데이터베이스 버전별 Parameter 변경 확인 (Database Reference 참고)
- v$parameter
- CREATE pfile=’initorcl.ora’ FROM spfile=’spfileorcl.ora’;
- ALTER SYSTEM SET undo_retention=10800 scope=memory;
- SCOPE
- MEMORY : 현재 오라클 인스턴스에 바로 반영
- SPFILE : spfile에 반영
- BOTH : default 값으로 둘 다 반영
- static parameter는 값 변경 후 DB 재시작 후 반영
- dynamic parameter는 값 변경 후 DB 재시작 후 반영
- Alter Log
- 맨 처음 로그 확인..
- $ORACLEBASE/diag/rdbms/db_name/sid/trace/altersid.log
- Trace Files
- 서버 프로세스와 백그라운드 프로세스에 관련된 Trace file
- Automatic Diagnostic Repository(ADR)은 SR 처리를 원할하게 하기 위해 생김.
1.3.2 메모리 아키텍처
- 오라클 데이터베이스 기본 메모리 구조
- UGA ( User Global Area )
- 사용자 세션 정보 저장
- 세션이 PL/SQL 패키지를 메모리에 로드하면 UGA는 패키지 변수에 변수 보관
- Session variables
- 세션 변수(로그인 정보와 데이터베이스 세션에 필요한 기타 정보)에 할당된 메모리(세션 상태 포함)
- OLAP Pool
- 데이터 블록과 동일한 OLAP 데이터 페이지를 관리
- 사용자가 dimensional object(ex:큐브)를 쿼리할 때 OLAP 세션이 자동 오픈
- Shared server의 경우 세션 정보 공유를 위해 UGA가 SGA에 존재
- Dedicated server의 경우 UGA가 PGA에 존재
Connection Type
- Dedicated Server동시 사용자 프로세스가 10개이면 서버 프로세스가 10가 생성되어 처리하는 방식( user : server = 1:1 )
- Shared Server
- 여러 사용자 프로세스는 서버 프로세스가 아닌 디스패처 프로세스에 네트워크를 통해 처리하는 방식
- Dispatcher :
- 사용자 프로세스와 공유 서버 프로세스(Shared Server Process) 사이에서 파이프처럼 작동
- 사용자 요청을 SGA 요청 큐(request queue)에 전달
- SGA 응답 큐(response queue)에 공유 서버 프로세스가 처리한 결과가 들어오면 사용자에게 전달
- PGA ( Program Global Area )
- 시스템의 다른 프로세스가 공유하지 않는 메모리
- 전용 또는 공유 서버 프로세스에 필요한 세션 종속 변수를 포함
- 서버 프로세스는 PGA에서 필요한 메모리 구조를 할당
- Private SQL Area : 구문 분석된 SQL 문과 처리를 위한 기타 세션별 정보 보관
- SQL Work Area
- 메모리 집약적 작업(Sort, Hash join, 비트맵 인덱스에서 검색된 데이터 병합)에 사용되는 PGA 메모리의 전용 메모리
- Sort 작업 중에 메모리가 부족하면 Temp(?) 사용
- SGA ( System Global Area )
- 오라클 데이터베이스 인스턴스에서 읽기/쓰기 메모리 영역
- DB 인스턴스 시작 시에 SGA에 대한 메모리가 자동 할당되고 인스턴스 종료시 메모리를 회수
- 서버 프로세스와 백그라운드 프로세스는 SGA가 아닌 별도의 메모리 공간에 존재
- Buffer Cache
- 데이터 파일에서 읽은 데이터 블록의 사본을 저장하는 메모리 영역
- 데이터베이스는 캐시에서 데이터 블록을 업데이트하고 redo 로그 버퍼의 변경사항에 대한 메타데이터를 저장
- commit 후에도 데이터 블록을 데이터 파일에 즉시 쓰지 않고 Database Writer(DBW)는 백그라운드에서 분산하여 씁니다.
- Least recently used(LRU) 기반으로 자주 액세스되는 블록을 버퍼 캐시에 보관하고 그렇지 않은 블록을 디스크에 씁니다.
- 데이터베이스에는 표준 블록 크기가 있고 표준 크기와 다른 크기로 테이블스페이스를 만들 수 있어 기본이 아닌 각 블록 크기별 자체 풀 생성 가능.(Multi block 사용 가능하지만 보통 사용하진 않음 -2k,4k,8k(Default), 16k)
- keep pool : 자주 액세스되지만 기본 풀에서 오래된 블록을 보관
- recycle pool:드물게 사용되는 블록으로 가장 먼저 메모리에서 일려남.
- Redo log Buffer
- SGA 내의 순환 버퍼로 데이터베이스 변경사항인 리두 엔트리를 저장
- 데이터베이스 프로세스는 사용자 메모리 공간(UGA)에서 SGA의 리두 로그 버퍼로 리두 엔트리를 복사
- Log Writer(LGWR) 프로세스는 리두 로그 버퍼를 디스크의 온라인 리두로그 파일에 순차적으로 씁니다.
- Shared Pool
- 다양한 유형의 프로그램 데이터를 캐시
- 공유 풀은 구문 분석된 SQL, PL/SQL 코드, 시스템 매개변수 및 데이터 사전 정보를 저장
- Library Cache
- 실행 가능한 SQL, PL/SQL 코드를 저장하는 공유 풀 메모리
- SQL 문이 실행되면 데이터베이스는 이전에 실행된 코드를 재사용하려고 시도하는 데 구문 분석된 SQL이 라이브러리 캐시에 존재하면 Soft Parse라고 하여 재사용 가능하지만 그렇지 않으면 SQL 구문을 빌드하는 데 이를 Hard Parse라고 함.
- Data Dictionary Cache
- 데이터베이스, 데이터베이스 구조, 사용자에 대한 참조 정보(권한)를 포함하는 데이터베이스 테이블과 뷰의 모음.
- SQL 구문 분석을 위해 사용됨
- Server Result Cache
- 공유 풀 내의 메모리 풀
- 버퍼 풀과 달리 데이터 블록이 아닌 결과 세트를 보관
- 클라이언트 결과 캐시는 데이터베이스 메모리가 아닌 클라이언트 메모리에 위치
- Large Pool
- 공유 풀보다 더 큰 메모리 할당을 위한 메모리 영역
- 공유 서버(shard server) 및 XA 인터페이스용 UGA(세션을 풀로 공유하여 사용하기 위한 용도 – 미들웨어처럼 )
- 병렬 실행에서 사용되는 메시지 버퍼
- Recovery Manager(RMAN) I/O 슬레이브용 버퍼
- Java Pool
- Java Virtual Machine(JVM)내의 모든 세션별 Java 코드와 데이터를 저장하는 메모리 영역
1.3.3 프로세스 아키텍처
- Mandantory Background Processes
- Process Monitor Process(PMON) Group
- 버퍼 캐시 정리와 종료된 클라이언트 프로세서가 잡고 있는 리소스 해제를 감독
- Process Monitor Process(PMON) : 다른 백그라운드 프로세스의 종료를 감시
- Cleanup Main Process(CLMN) : 종료된 프로세스, 세션, 트랜잭션, 네트워크 연결 등을 주기적으로 정리
- Cleanup Helper Processes(CL nn) : 종료된 프로세스와 세션 정리를 지원
- Process Manager(PMAN)
- 공유 서버, 풀 서버, 작업 대기열 프로세스를 포함한 여러 백그라운드 프로세스를 모니터링 및 생성/중지
- Listener Registration Process(LREG)
- 데이터베이스 인스턴스와 디스패쳐 프로세스에 대한 정보를 Oracle Net Listener에 등록
- 12c이전에는 PMON이 리스너 등록을 수행
- System Monitor Process(SMON)
- 시스템 수준 정리 업무를 담당
- 인스턴스 시작 시 인스턴스 복구 수행
- 파일 읽기 또는 테이블스페이스 오프라인 오류로 인해 종료된 트랜잭션을 복구
- 사용되지 않는 임시 세그먼트 정리
- Dictionary-managed 테이블스페이스 안에서 인접한 여유 익스텐트를 통합
- Database Writer Process(DBW)
- 데이터베이스 버퍼 캐시의 수정된 버퍼를 디스크에 기록
- 비동기적으로 더티 버퍼를 디스크에 기록
- 체크포인트 발생 시 디스크 기록
- 오라클이 권고하는 DBWR 프로세스 개수는 CPU_COUNT/8
- Log Writer Process(LGWR)
- 리두 로그 버퍼의 일부를 온라인 리두 로그에 기록
- 리두 로그 스위치 발생 시 기록
- 사용자가 commit을 실행하면 트랜잭션에서 System Change Number(SCN)이 할당되어 LGWR은 커밋 레코드를 리두로그 버퍼에 넣고 커밋 SCN과 트랜잭션의 리두 엔티티를 즉시 디스크 씁니다.
- LGWR은 트랜잭션이 커밋되기 전에 디스크에 REDO 로그 엔티티로 쓸 수 있습니다. 다만 리두 엔티티로 보호되는 변경사항은 트랜잭션이 나중에 커밋되는 경우에만 영구적이 됩니다.
- Checkpoint Process(CKPT)
- 체크포인트 정보로 컨트롤 파일과 데이터 파일 헤더를 업데이트하고 DBW에 블록을 디스크에 쓰도록 신호를 보냅니다.
- 체크포인트 정보는 체크포인트 위치, SCN, 온라인 리두로그 위치가 포함
- 리두로그 스위치시에 checkpoint 발생
- 테이블스페이스 오프라인 및 백업 시작
- 데이터베이스 정상 종료 시시
- Process Monitor Process(PMON) Group
- Optional Background Processes
– Archiver Processes(ARCn)
– 리두 로그 스위치가 발생한 후 온라인 리두 로그 파일을 오프라인 저장소로 복사
– Job Queue Processes(CJQ0 and Jnnn)
– 큐 프로세스는 배치 모드로 user job에서 실행
– 예약된 사용자 정의 작업
– Flashback Data Archive Process (FBDA)
– tracked table에 dml이 포함된 트랜잭션이 커밋되면 이 프로세스는 변경된 행의 이전 이미지를 플래시백 데이터 아카이브로 저장1.3.4 Oracle Net Service Architecture - Oracle Net Listener
- 클라이언트 연결 요청을 수신하고 데이터베이스로의 트래픽을 관리하는 서버 측 프로세스
- Service Name
- 클라이언트 연결에 사용되는 서비스의 논리적 표현
- 리스너로 알려진 서비스는 하나 이상의 데이터베이스 인스턴스를 식별
- Service Registration
- LREG 프로세서가 리스터에 인스턴스 정보를 동적으로 기록
- 서비스 등록은 동적이며 listener.ora 파일에 구성이 필요 없음.
- tnsping은 TCP/IP의 핑(ping) 유틸리티와 동일한 Oracle Net 유틸리티로 네트워크 경로가 유효한지 신속하게 확인 가능
- Security
- 권한의 모음이 ROLE
- Concurrency
- ORALE은 데이터의 동시성 관리를 위해 ROW단위로 LOCK 제공
- UNDO
- 오라클 데이터베이스는 트랜잭션 rollback, 데이터베이스 복구의 일부로 읽기 일관성을 제공하고 oracle flashback query 기능을 활성화 하기 위해 undo 데이터를 사용
- UNDO_RETENTION
- 일관성 읽기를 위해 제공되는 Undo 데이타의 보유 기간
- 900초(15분)가 기본 -> 10800초로 수정.
2. High Availability
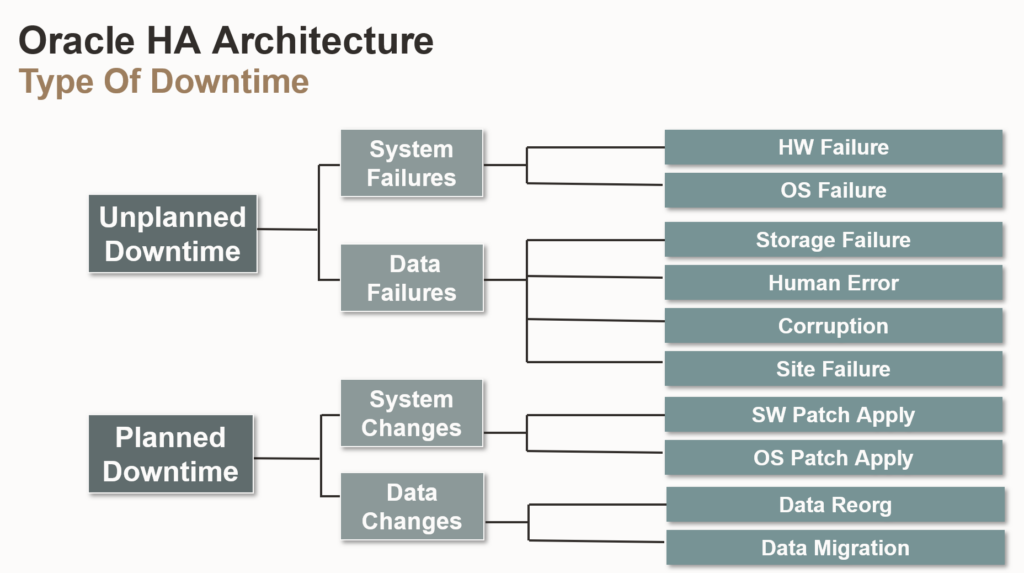
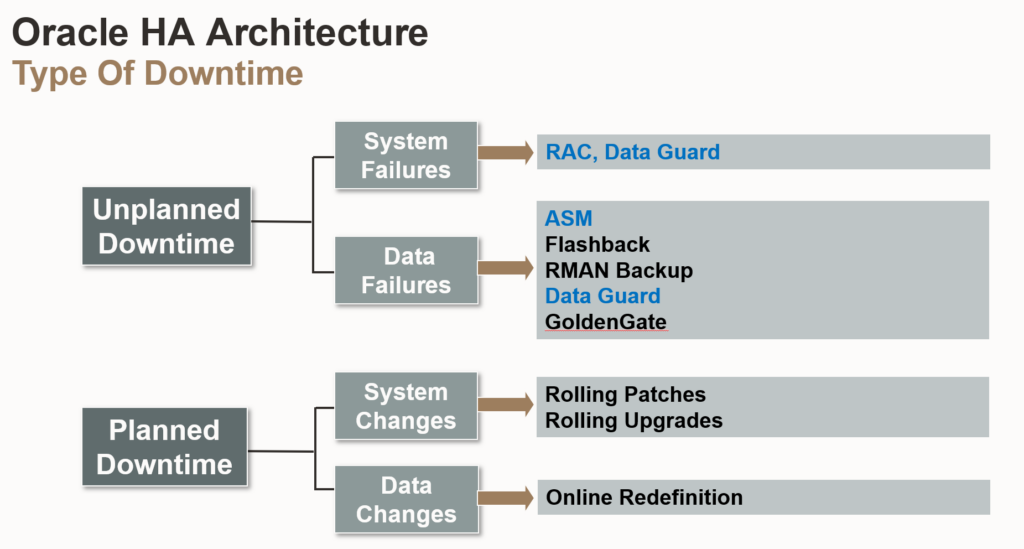
- RAC
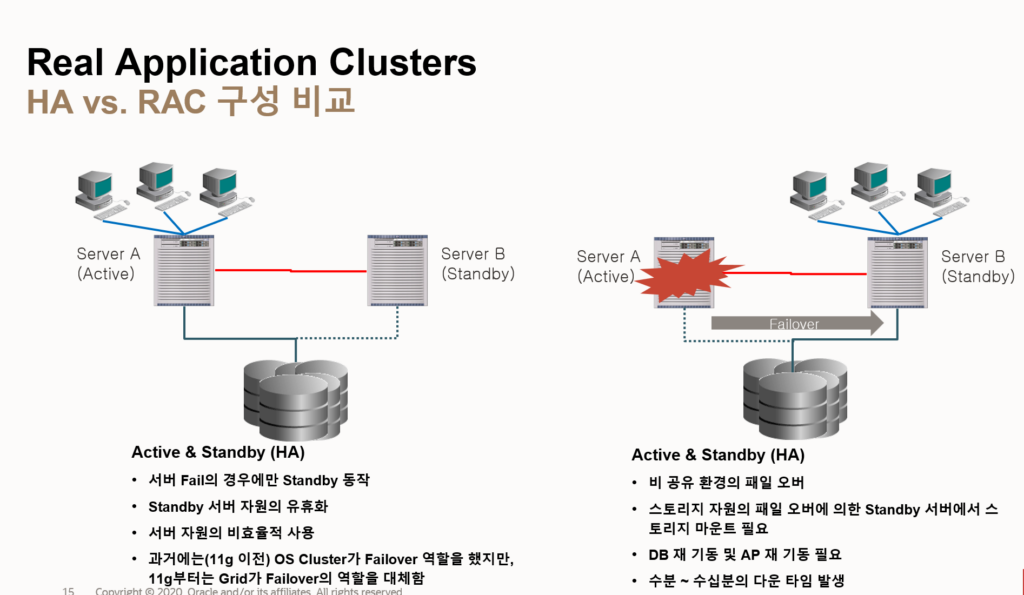
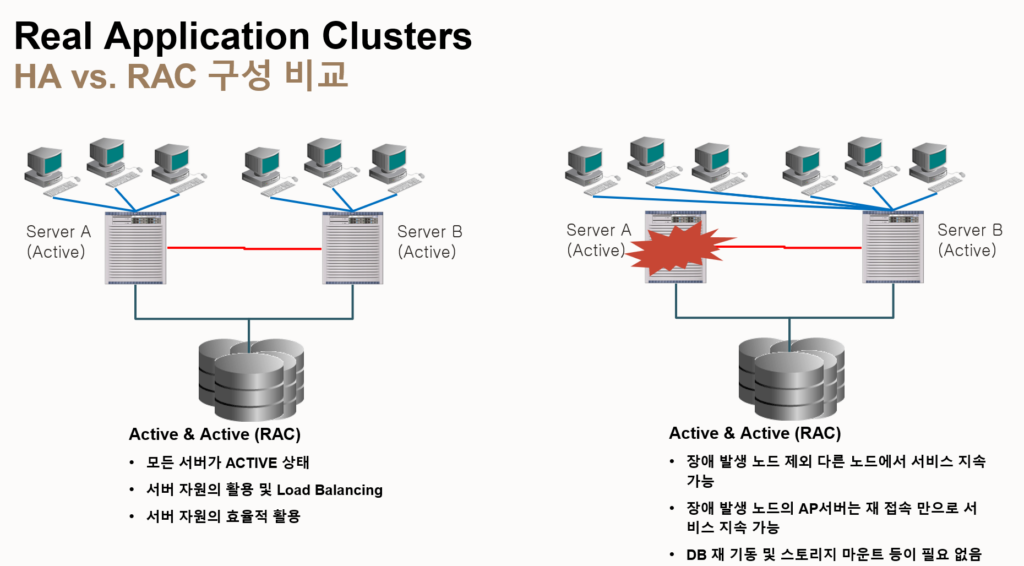
- RAC에서 data buffer cache를 각 인스턴스 끼리 데이터 전달을 해야하므로 interconnect 속도가 중요(전용 스위치를 구성필요)
- oracle clusterware
- Session Failover – TAF / CTF
- Connect –Time Failover(CTF)
- RAC 고객은 TNSNAMES.ora 파일에서 node1이 문제가 생겼을 때 PUBLIC IP의 경우 클러스터웨어가 문제를 확인하는데 오래 걸리는데 VIRTUAL IP를 사용하면 클러스터가 바로 확인하여 node2로 이동
- Transparent Application Failover (TAF)
- 문제가 발생한 노드의 select만 정상적인 노드로 이동하여 작업 시킴
- select 이외의 작업은 모두 끓김.
- split brain
- 네트워크 문제 (인터커넥터) 문제로 인해 인스턴스간 캐시 공유가 어려우면 클러스터웨어가 문제가 생기면 split brain기능으로 데이터 정합성을 위해 두 서버 중 한 서버를 reboot시킴.
- Exa의 경우 2(normal) or 3(high) 중화하여 데이터 스토리지를 복제하고 이외 스토리지의 경우 스토리지 자체에 이중화가 되어 있어 os에서 이중화를 할 필요없음.
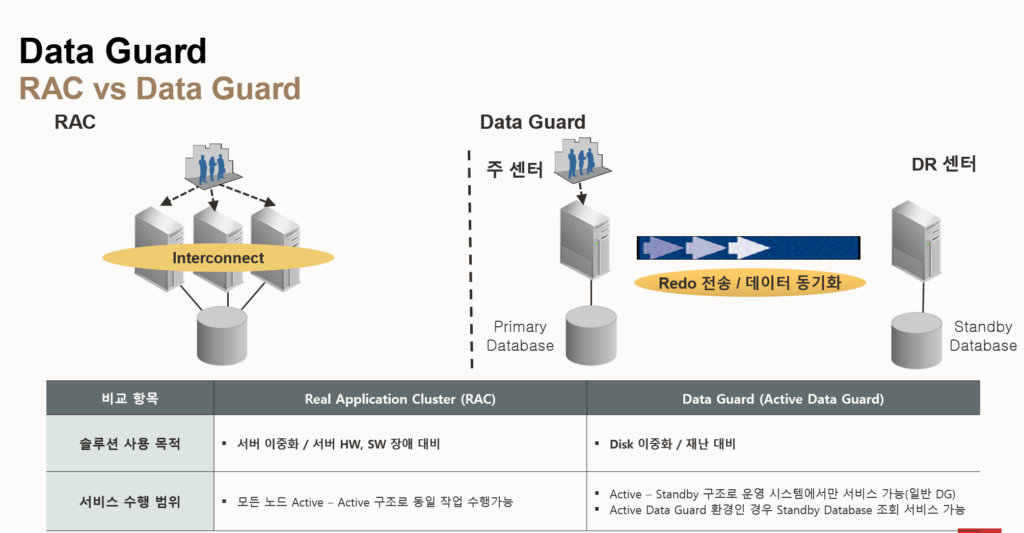
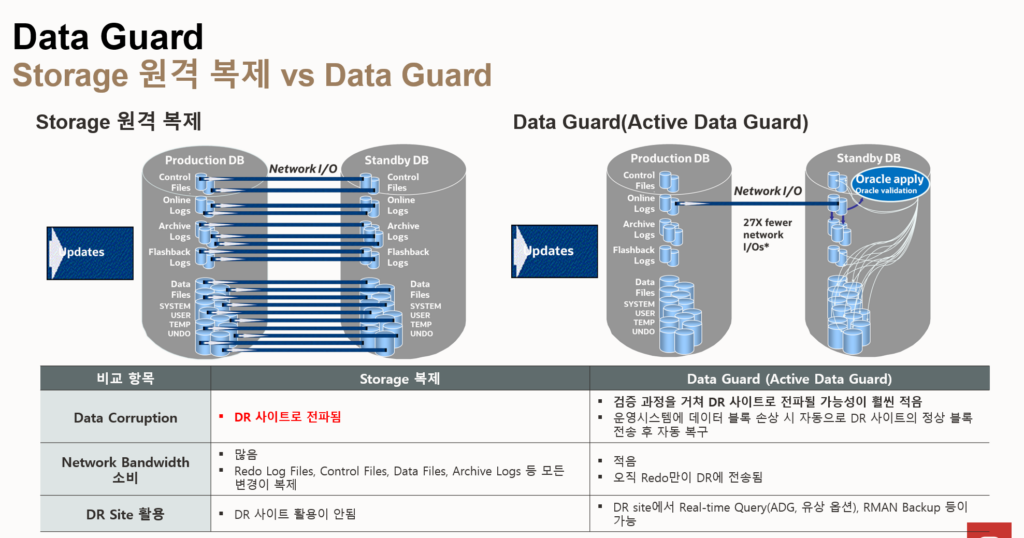
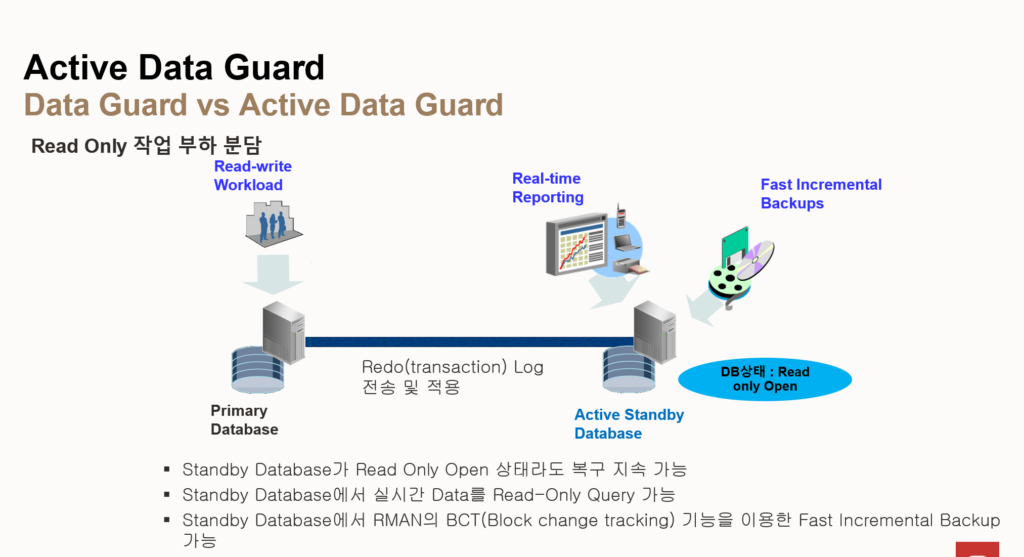
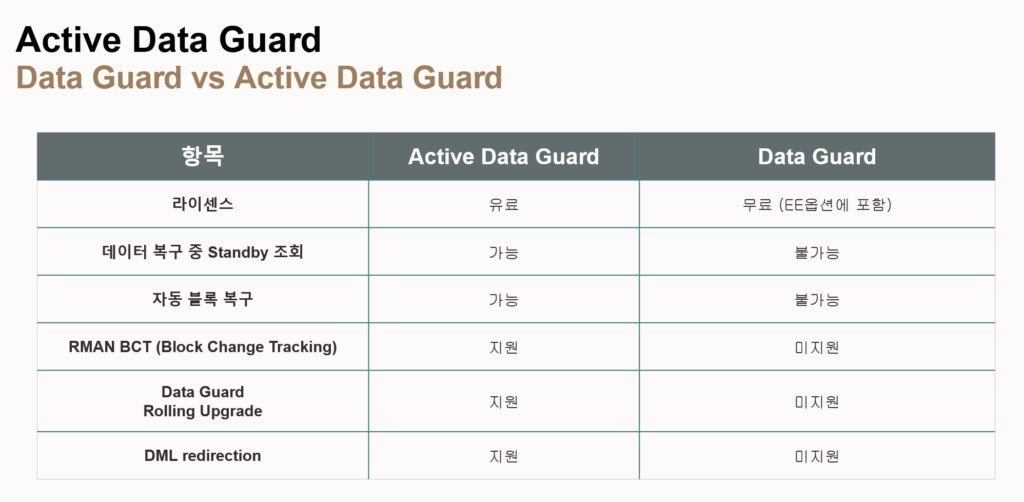
- Data Guard
- data guard는 서버 및 디스크 이중화 ( 재난 대비 )
- data guard는 redo 로그 파일 자체를 전송 ( ogg는 trail 파일에 sql을 전송)
- data guard broker
- DG 생성, 관리, 모니터링 업무를 중앙 관리 가능(Enterprise Manager)
- switch over : 개발이나 테스트 등의 이유로 역할 변환
- fail over : 주 센터가 문제가 발생했을 때 연결을 끊고 스텐바이 센터를 주센터로 바꿈…주센터는 더 이상 사용 불가하여 이제 초기화해서 재 작업 필요
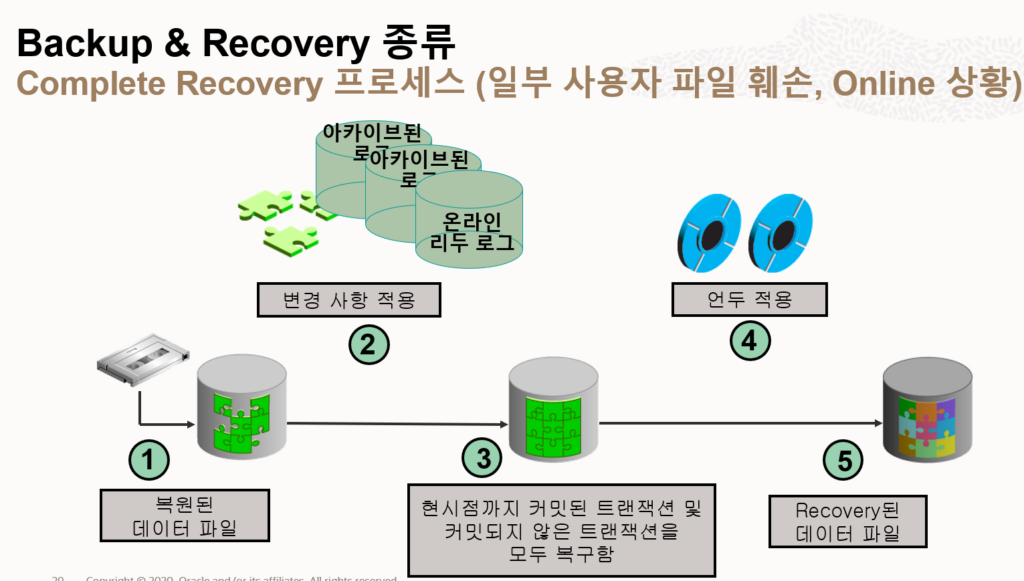
3. Backup and Recovery
- Checkpoint Process


- SMON 수행
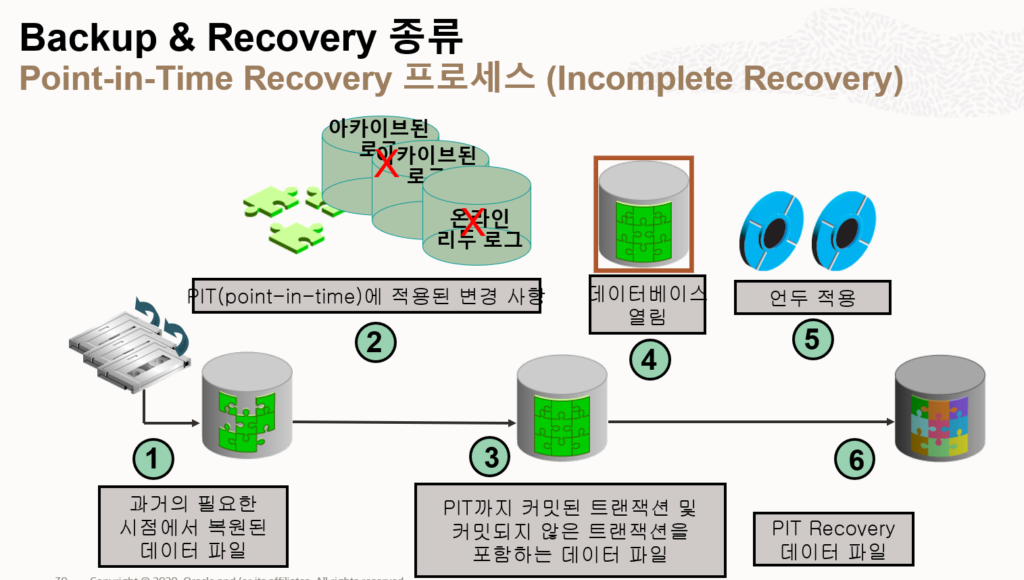
- alter database open resetlogs;
- flashback(+ achive mode 필수)
- COMMIT 수행 후 특정 시점으로 되돌릴 수 있는 기능
- flashback database : flashback logs 확인
- flashback table : undo data로 확인
- flashback transaction : undo data로 확인